Basics
In
an earlier article, I had listed the review of JVM memory parameters as one of the important checks for tuning the JEE server platform.
The basic primer for JDK 1.4 is at
http://java.sun.com/docs/hotspot/gc1.4.2/The key points you need to know are:
Total JVM Heap = Young + Tenured(also called Old)
Young = Eden + From (SS1) + To (SS2)
In the diagram below [taken from the Sun website], "From" and "To" are the names of the two Survivor Spaces (SS) within the "Young".
Perm Space (and code cache): stores JVM’s own stuff. This is
outside the Heap you assign using Xms and Xmx. A good explanation of this is available
hereThe JVM Heap is at default initial 2Mb and max 64Mb (for JDK 1.4 on Solaris).
Default Perm Size is 16MB (for JDK 1.4 on Solaris)
The defaults change for each JDK and are different on each OS - so look up the values on the respective websites.

The ratios are as shown below
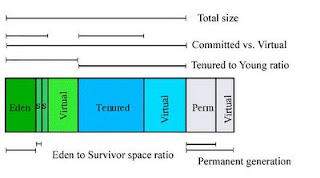
Now the object life cycle and garbage collection occurs like this:
1. Objects when created are always first allocated to Eden.
2. When Eden fills up, a fast but not comprehensive GC (minor collection) is run over the young generation only.
3. All surviving objects are moved from Eden into one Survivor Space.
4. In consequent minor collections, new objects move from Eden into the other Survivor Space, plus everything from the first Survivor Space (survivors from the previous minor collection) is also moved into the second Survivor Space. Thus one survivor should be empty at that time.
5. When objects in Survivor Space are old enough (or survivor fills up), they are moved to Tenured. By default the long-lived objects may be copied up to 31 times between the Survivor Spaces before they are finally promoted to the Old generation.
6. When tenured fills up, a Full GC collection is run that is comprehensive: the entire heap is analyzed, all objects that can be destroyed are killed and memory is reclaimed.
Note: the above lifecycle changes slightly when advanced options such as ConcurrentMarkSweep etc are enabled.
Look Closer
What do these values mean ?
A full list of options available at http://java.sun.com/docs/hotspot/VMOptions.html and http://java.sun.com/javase/technologies/hotspot/vmoptions.jsp
The absolute basic ones are listed in the table below. Note: This is for JDK 1.4
Some of these have changed in JDK 1.6
| -Xms1536m -Xmx1536m | These represent the total heap (minus Perm space). Xms is the Initial Heap, set to 1.5Gb in this case. Xmx is Max Heap. It is good practice to set Xms = Xmx
The max heap is limited by the RAM available on the server |
| -XX:NewSize=512m | This specifies the initial size of the Young generation,set to 512Mbin this example. It is better to set this as a percentage of the Heap using -XX:NewRatio |
| -XX:MaxNewSize=512m | This specifies the maximum size of the Young generation,set to 512Mbin this example. It is better to set this as a percentage of the Heap using -XX:MaxNewRatio |
| -XX:PermSize=64m -XX:MaxPermSize=128m | These values are the Minimum and Maximum sizes of the permanent generation heap space. Optimally, set PermSize equal to MaxPermSize to avoid heap having to be adjusted when permanent area grows. As specified earlier, this area of memory is over and above the Total Heap set using Xms
|
| -XX:SurvivorRatio=8 -XX:TargetSurvivorRatio=90 | The New generation area is divided into three sub-areas: Eden, and two survivor spaces that are equal in size. Use the -XX:SurvivorRatio=X option to configure the ratio of the Eden/survivor space size. In the above example, setting it to 8 means the ratio of Eden:SS1:SS2 is 8:1:1. So for a NewSize of 512 Mb, the two SS will be 51 Mb each, and Eden will be 512 MINUS (51 + 51) = 410 Mb.
TargetSurvivorRatio of 90 allows 90% of the survivor spaces to be occupied instead of the default 50%, allowing better utilization of the survivor space memory.
|
| -XX:MaxTenuringThreshold=10 | This switch determines how many times the objects are hopped between the Survivor spaces before getting promoted to the older generation. The default value is 31. |
| -XX:+DisableExplicitGC | |
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintTenuringDistribution -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCApplicationStoppedTime -Xloggc:/log/gc.log
| These are GC specific settings asking for GC details and the log file name in which these details should be captured |
If you have an appetite for more, read this http://java.sun.com/performance/reference/whitepapers/tuning.html
GCViewerThis link below explains how to download and use the GCViewer tool. This is quite a useful tool for viewing the number of GCs and Full GCs and how the JVMis behaving over time.
http://www.javaperformancetuning.com/tools/gcviewer/index.shtmlThe most important things to look at in the GCViewer analysis are the
* Acc Pauses -
Accumulated Pause Time (total time app was stopped for GC).Pauses are the times when an application appears unresponsive because garbage collection is occurring
* Total Time - Total Time the application runs.
* Throughput - Time the application runs and is not busy with GC.
Greater than 99% is fantastic.Throughput is the percentage of total time not spent in garbage collection, considered over long periods of time.
* Footprint - Overall Memory Consumption - Ideally as low as possible. This is the working set of a process, measured in pages and cache lines. On systems with limited physical memory or many processes, footprint may dictate scalability. Thus this usually reflects the size of total Heap allocated via Xms and Xmx
This diagram is taken from the above site:
 Tuning Example From the Trenches - Frequent GC due to Perm Space getting FullJVM Parameters already set
Tuning Example From the Trenches - Frequent GC due to Perm Space getting FullJVM Parameters already setjava -server -Xms1024m -Xmx1024m -XX:MaxPermSize=340m -XX:NewSize=340m -XX:MaxNewSize=340m
-XX:SurvivorRatio=9 -XX:TargetSurvivorRatio=90 -XX:+UseParNewGC
-Xloggc:/wls_domains/gclog/jms.gc -XX:+PrintGCDetails -XX:+UseParNewGC
-XX:+PrintGCTimeStamps -XX:+DisableExplicitGC -XX:+PrintTenuringDistribution
-XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCApplicationStoppedTime
-XX:+JavaMonitorsInStackTrace -Dweblogic.system.BootIdentityFile=/wls_domains/xx/boot.properties
-Dweblogic.management.server=http://xx.xx.xx.xx:6000 -Dweblogic.Name=xxxxxx
-Dweblogic.ProductionModeEnabled=true
-Djava.security.policy=/opt/bea/wls/8.1sp4/weblogic81/server/lib/weblogic.policy
weblogic.Server
Full GC PatternThe GC log shows
0.000: [Full GC 0.000: [Tenured: 0K->9794K(700416K), 0.8050952 secs] 134607K->9794K(1016960K), [Perm
: 20479K->20479K(20480K)], 0.8053527 secs]
First Full GC happens at 0:00 sec from start of server. Before and after '->' figures represent size of live objects before and after GC. Number in parenthesis indicates total available space. So from above numbers - Tenured was not full but Perm was almost full.
6579.013: [Full GC 6579.013: [Tenured: 9794K->18941K(700416K), 0.9677233 secs]
155600K->18941K(1016960K), [Perm : 24575K->24575K(24576K)], 0.9679896 secs]
Same thing happens here. The second Full GC took place at 6579.013 sec (1hr 49mins) from startup of server.
Again a Full GC is triggered, but the Tenured was not full. The Tenured is now 18.9 Mb out of 700 Mb - but it is seen the Perm Space has grown to 24.5 Mb and is not getting cleared.
9363.515: [Full GC 9363.516: [Tenured: 18941K->19463K(700416K), 0.6532332 secs] 36950K->19463K(1016960K), [Perm : 28672K->26462K(28672K)], 0.6536095 secs]
At the 3rd Full GC at 9363 seconds after server startup, the Perm space grew to 28.6 Mb and recovered marginally to 26.4 Mb.
Observing this over a long period of time, we concluded that at startup around 20MB is allocated to perm which with each Full GC keeps growing till 30MB and later shrinks back to 25MB and the cycle continues.
The pattern is highlighted below:
0.000: [Full GC 0.000: [Tenured: 0K->9794K(700416K), 0.8050952 secs] 134607K->9794K(1016960K), [Perm : 20479K->20479K(20480K)], 0.8053527 secs]
6579.013: [Full GC 6579.013: [Tenured: 9794K->18941K(700416K), 0.9677233 secs] 155600K->18941K(1016960K), [Perm : 24575K->24575K(24576K)], 0.9679896 secs]
9363.515: [Full GC 9363.516: [Tenured: 18941K->19463K(700416K), 0.6532332 secs] 36950K->19463K(1016960K), [Perm : 28672K->26462K(28672K)], 0.6536095 secs]
13483.233: [Full GC 13483.233: [Tenured: 19463K->16962K(700416K), 0.9783693 secs] 26678K->16962K(1016960K), [Perm : 30719K->21330K(30720K)], 0.9857390 secs]
17308.829: [Full GC 17308.830: [Tenured: 16962K->17312K(700416K), 1.0578872 secs] 88025K->17312K(1016960K), [Perm : 25600K->25600K(25600K)], 1.0581738 secs]
21237.810: [Full GC 21237.810: [Tenured: 17312K->17814K(700416K), 1.4728764 secs] 302290K->17814K(1016960K), [Perm : 29695K->26719K(29696K)], 1.4801234 secs]
30079.672: [Full GC 30079.672: [Tenured: 17814K->18676K(700416K), 1.0282446 secs] 83159K->18676K(1016960K), [Perm : 30975K->27564K(30976K)], 1.0349869 secs]
Solution:Though the MaxPermSize=340m is provided, initial available Perm Size is getting full and JVM is invoking a Full GC to free up memory. The default initial PermSize is 16Mb and hence the Perm Space is resizing itself as the JVM grows.
Not sure if this behaviour is a bug but by adding an initial PermSize of 64K using this flag -XX:PermSize=64m resolved this issue of frequent Full GC.
UPDATE: Another examples published on
http://jojovedder.blogspot.com/2009/07/jvm-tuning-from-trenches.html











